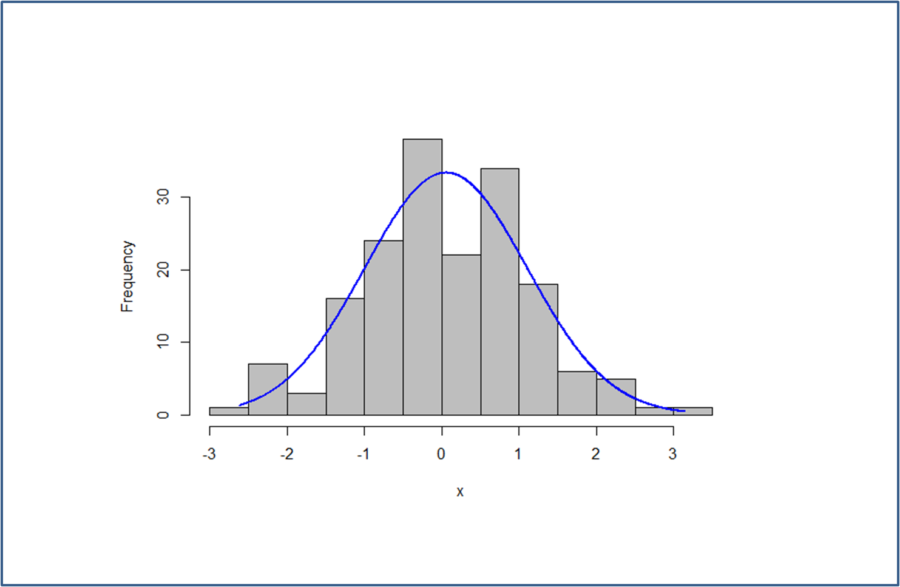
Обзор публикаций по вопросам приведения данных к нормальному виду дал такие интересные выводы:
1) Нет ничего противозаконного в том, чтобы работать с преобразованными данными, главное – выводы на преобразованных данных суметь перевести на исходные данные (например, здесь: http://www.biostathandbook.com/transformation.html). Это может быть проблематично в случае использования сложных преобразований, например, преобразований Джонсона.
2) Существует бесконечное множество преобразований, и если много тренируешься, то рано или поздно найдешь способ привести данные к нормальности, при этом со стороны это может выглядеть как попытка подстроить результат. Потому советуют, что лучше воспользоваться консервативным методом трансформации и уступить в p-value, чем достичь большей значимости неким диковинным преобразованием.
3) Нужно быть готовым защищать свои методы, т.к. многие люди не имеют представления о сути преобразований данных, а потому будут скептично воспринимать эти подходы.
4) Способы определения нормальности распределения: визуально по гистограмме и qqplot, при помощи статистических тестов.
5) qqplot часто может ввести в заблуждение, т.к. отклонение от прямой линии очень зависит от объема выборки (ниже qqplot` ы сгенерированные функцией rnorm для 30 и 300 значений соответственно:

6) Чтобы не полагаться на «глазомер» лучше строить qqplot`ы сразу с доверительными интервалами. Есть хорошее решение в пакете «car» – функция qqPlot. Но в этой случае тоже можно ошибиться, т.к. на примере ниже данные не распределены нормально ни по данным гистограммы, ни по тесту Шапиро-Уилка, но qqplot содержит все точки в пределах границ доверительного интервала:
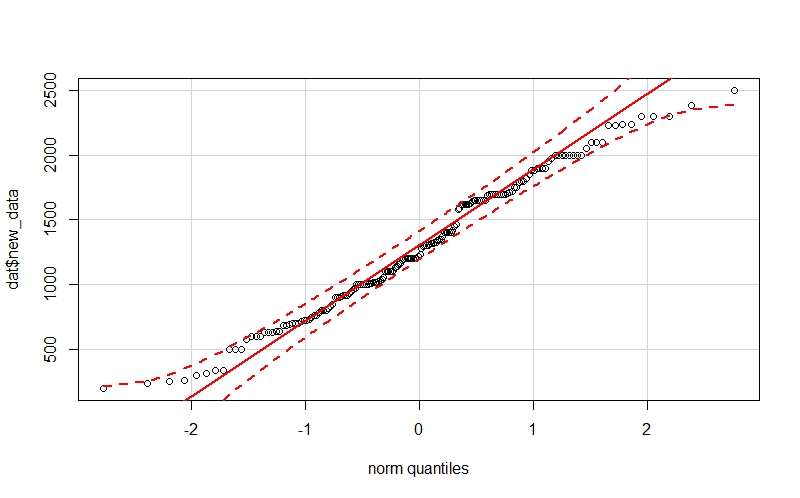
7) Что касается статистических тестов, то наиболее популярными и надежными являются тесты Шапиро-Уилка и Андерсона-Дарлинга, однако упоминается о массе случаев, когда тесты дают сбой, например, здесь: https://www.r-bloggers.com/normality-tests-don%E2%80%99t-do-what-you-think-they-do/
Вывод здесь может быть только такой: принимать решение о нормальности распределения на основании анализа вида распределения, qqplot`а, а также данных тестов.
8) Без ПО никуда, т.к. перепробовать множество разных методов трансформации вручную просто невозможно. Анализ данных карандашом сейчас никто не делает…
9) Прежде чем начать преобразование данных нужно удалить экстремальные значения. Поскольку в ненормальных распределениях мы не может воспользоваться критериями, например, межквартильного расстояния (IQR), то в данном случае речь идет о выбросах, что вызваны ошибками в записи данных. Исследователь сам принимает решение о том, насколько логичны полученные им значения и какие из них стоит убрать из массива.
10) Наиболее предпочтительные преобразования: log10(x), ln()x, sqrt(x), 1/x, asin(x).
11) Популярными являются степенные преобразования (power transformations) Box-Cox power transform и Tukey Ladder of Powers, например здесь: http://rcompanion.org/handbook/I_12.html
12) Но есть подтверждения тому, что преобразования Джонсона более эффективны (http://www.sigmamagic.com/forum/archives/297). Эти преобразования включают функции:
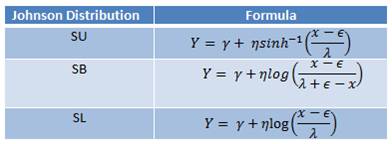
Обратных функций к SU, SB и SL найти не удалось, однако использование функции jtrans из одноименного пакета позволяет узнать и вид функции и значения параметров преобразования Джонсона (гамма, ипсилон, лямбда, эта), т.е. обратные значения можно подобрать.

Залишити відповідь