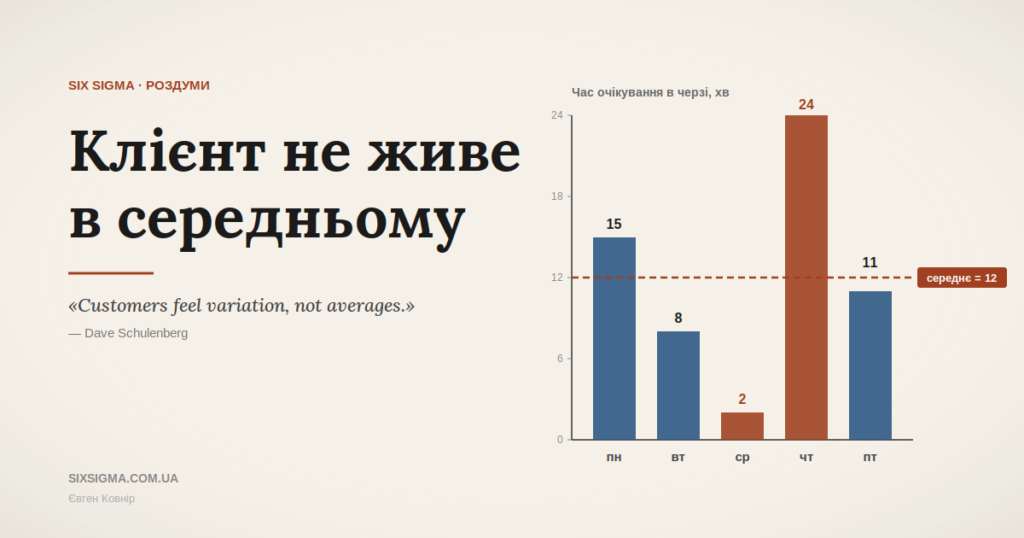
 У книзі Джорджа Екеса про Six Sigma є сцена, яка на перший погляд здається буденною: фастфуд, черга, середній час очікування цього тижня — 12 хвилин. У вівторок ти стояв 2 хвилини, у четвер — 24. І цитата його колеги Дейва Шуленберга, через яку легко проскочити, не помітивши, що вона перевертає весь спосіб дивитися на управління:
У книзі Джорджа Екеса про Six Sigma є сцена, яка на перший погляд здається буденною: фастфуд, черга, середній час очікування цього тижня — 12 хвилин. У вівторок ти стояв 2 хвилини, у четвер — 24. І цитата його колеги Дейва Шуленберга, через яку легко проскочити, не помітивши, що вона перевертає весь спосіб дивитися на управління:
Customers feel variation, not averages.
Клієнт відчуває варіацію, не середнє.
Зупинюсь тут, бо за цією простою фразою — розрив онтологій. Клієнт живе у світі одиничних подій: цей вівторок, цей четвер, цей конкретний обід, через який треба встигнути повернутись у офіс. Менеджмент дивиться на агрегати: середній час обслуговування, середній чек, середня задоволеність за квартал. І ці два світи не зводяться один до одного. Середнє не є “грубим наближенням” клієнтського досвіду — це інший об’єкт. У світі клієнта 12-хвилинної черги не існує. Її не було ні у вівторок, ні у четвер.
Тобто управління керує об’єктом, якого у світі клієнта просто немає.
Звідси кілька наслідків, які варто промацати.
Зворотний зв’язок викривлений за конструкцією. Сигнал від клієнта народжується у просторі одиничних подій, а зчитується у просторі середніх. Поки 24-хвилинний четвер розчиняється в середньому, інформація про подію, яка реально вбила лояльність, уже стерта.
Хвости формують репутацію. Болючий епізод запам’ятовується непропорційно сильніше, ніж приємний — це базова асиметрія сприйняття. А саме хвости найкраще ховаються в середніх. Тобто управління середніми — це системне підсилення сліпих плям саме там, де відбувається втрата клієнта.
Передбачуваність — прихований товар, який ніхто не продає свідомо. Клієнт платить не лише за обід, а й за можливість планувати свій день. Цього товару немає в P&L, його не вимірює NPS, але саме він визначає, чи людина повернеться. Brown bagging — взяти з дому — це не альтернатива обіду. Це альтернатива ризику.
Середнє — це психологічний захист менеджера, а не інструмент. Варіація — це визнання того, що реальність не піддається повному контролю. Середнє повертає відчуття контролю там, де його структурно немає. Тому опір переходу від “поліпшити середнє” до “звузити розкид” — не методологічний, а екзистенційний.
Тут теза Шуленберга змикається з Демінгом. Демінг казав: 94% проблем — у системі, а не в людях. Шуленберг каже: клієнт живе у варіації, а не в середньому. Перший показує, де живе проблема. Другий — де живе клієнт. А управління традиційно сидить у третьому місці: у середніх показниках людської продуктивності.
Структурно дивиться не туди, де проблема, і не туди, де клієнт.
І тоді SPC, контрольні карти, робота з варіацією — це не “ще один інструмент серед інших”. Це зміна того, що взагалі вважається об’єктом управління. Купуєш не методику, а іншу онтологію.
Тому ця теза так важко продається керівництву. Не тому, що складна. Тому, що для неї спершу треба погодитись: ти все життя дивився не туди.